参考了 Megatron Core 官方 docs:
Megatron Core官方docs
点击查看Megatron Core官方文档Performance Best Practice章节
| 并行策略 | 峰值激活内存 | 权重内存 | 优化器状态 | 通信量(每层) |
|---|---|---|---|---|
| TP | 1/N (需开启序列并行 SP)) | 1/N | 1/N | 高 |
| EP | 1 | 1/N(MoE 层) | 1/N | 中 |
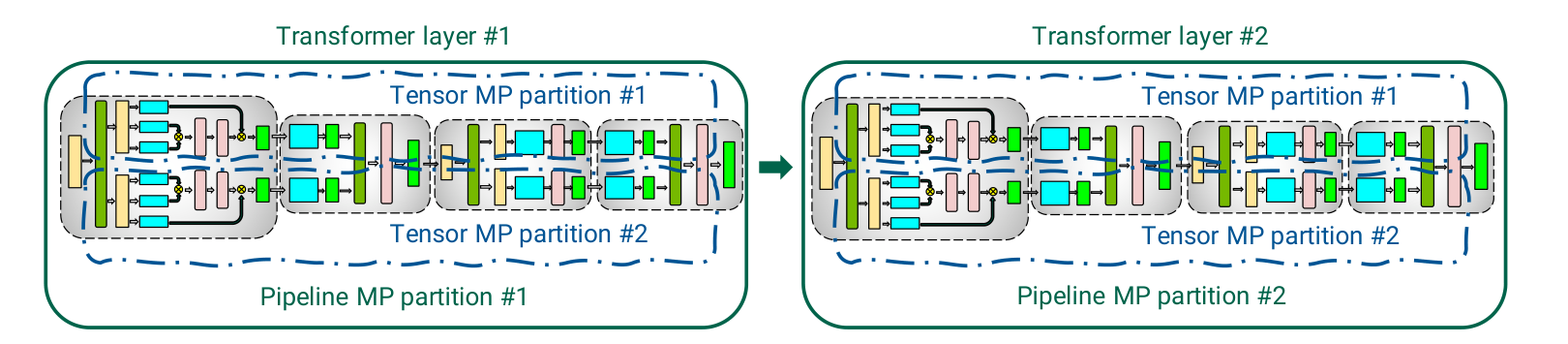
| PP | 1 (若启用虚拟流水线则>1) | 1/N | 1/N | 中 |
| CP | 1/N | 1 | 1/N (需使用分布式优化器) | 中 |
| DP | 1 | 1 | 1/N (需使用分布式优化器) | 低 |
- 多节点情况下先考虑 PP,再考虑 TP 和 EP,单节点反之
- EP 和 TP 的通信应尽可能保持在 NVLink 内
- 选择 EP 优先于 TP
- TP 比 EP 节省内存,但 EP 可以实现比 TP 更好的 GEMM 效率和更少的通信开销
- 对于 8x7B 的 MoE 模型,EP8TP1 的配置通常优于 EP4TP2
- 当训练序列长度非常长(经验值 >=8K)时,考虑使用 CP
